国际领先的“得意”声纹识别引擎
2005/07/20
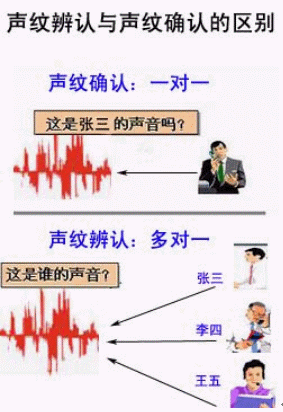
得意公司的声纹识别引擎(d-Ear VPR)包括声纹辨认版本和声纹确认版本,可以是文本无关的,也可以是文本相关的,而且均支持开集的识别方式。其中文本无关的版本同时具有文本和语言的无关性,对语音长度的要求也非常低,通常训练只需要几十秒有效语音,而识别阶段只需几秒钟的有效语音即可。有很高的识别精度,也可以灵活地调整操作点参数从而适应于不同应用的需求。
"得意"声纹识别技术与其他声纹识别技术的比较
|
得意声纹识别技术
|
其他声纹识别技术
|
|
| 1 | 具文本无关性,确保了身份确认的安全性和用户的方便性 对声纹的识别与所说的文本和语言无关,用户训练系统和系统对用户的声音进行鉴别和确认,可以是完全不同的文本,完全不同的语言。比如,在用户在系统注册声音时,可以使用中文说一段文学章节,而识别时用户可以用英文谈论计算机的发展方向。 |
与文本相关,安全性和使用方便性都显不足 对声纹的识别与所说的文本和语言相关,用户训练系统和系统对用户的声音进行鉴别和确认,必须是完全一致的文本,使用相同的语言,容易导致口令的外泄。 |
| 2 | 对语音长度没有特殊要求,方便实际的应用 使用时的测试语音2-4 秒,并可不断累积调整声纹模型精度;用户训练系统,让其记住其声纹,只需要几秒种的声音;而在识别时,系统只要获得被测试人几秒的声音,就可以进行声纹识别。 |
要求进行特定的语音训练,用户需跟着朗读和学习,方便性和实用性不强 |
| 3 | 很高的精度 得意的技术辨认和确认准确度都很高,说话人辨认的正确率不小于99%;说话人确认的误识率和误拒率均低于1% |
精度一般 识别精度约为90%,误识率和误拒率相对较高 |
| 4 | 操作点调整方便 可根据实际情况和环境,按不同的应用需求调整操作点阈值,使最终准确率达到最高或使错误率降到最低。 |
没有操作点调整功能 不同用户和不同的环境使用只能使用同一模型,不能确保高的安全性和准确率 |
| 5 | 声纹模型存储空间小 每个人的声纹模型存储空间小于5KB,能可靠地存储于加密钥匙内,与硬件紧密结合能最高程度地保证系统的安全性,防止非法的攻击和窃取 |
声纹模型存储空间小 不能存储于加密钥匙内,没有硬件的保护,不能有效防止非法的攻击和窃取 |
得意音通公司供稿 CTI论坛编辑
| 得意珠三角综合智能信息增值平台项目中标 2009-08-20 |
| 北京软件产品质量检测检验中心对《海量语音文件的目标说话人筛选系统》进行测试 2009-06-25 |
| 广东政府和清华大学举行了全面开展产学研合作协议签约仪式 2009-06-25 |
| 得意中文整句输入法V1.0开源for Windows Mobile5.0 2009-01-23 |
| 得意声纹识别VPR4.0_b20080808新版本发布 2008-08-27 |