自然流畅的文语转换系统——木兰
2004/06/11
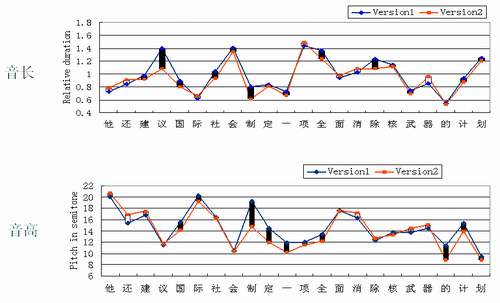
语音门户、呼叫中心、声讯服务等基于语音合成技术的文语转换应用已经越来越多地进入我们的工作和生活中。“木兰”是由位于北京的微软亚洲研究院研发并具有顶级性能的文语转换系统,木兰有哪些重要特点?木兰文语转换的真实应用效果如何?
CHIP新电脑
| Dynamics的“灵活”战略 2009-09-28 |
| 微软国内首推Push mail 酷派3G产品率先支持 2009-09-28 |
| 鲍尔默:我们搞砸了Windows Mobile 7 2009-09-25 |
| 微软全球基础服务部门副总裁离职加盟思科 2009-09-24 |
| 微软推最新手机操作系统WindowsMobile6.5 2009-09-04 |